GaWC Research Bulletin 50 |
|
|
|
This Research Bulletin has been published in Urban Studies, 39 (13), (2002), 2377-2394.
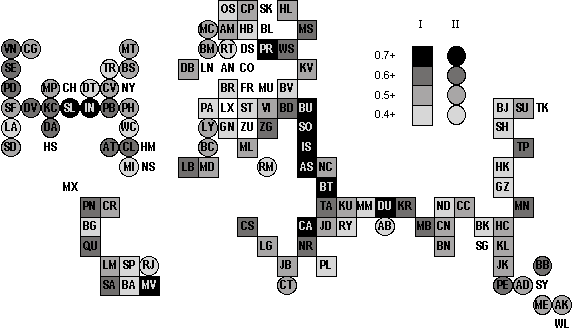
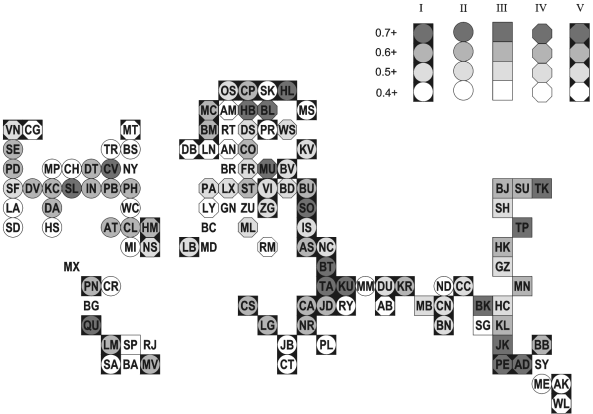
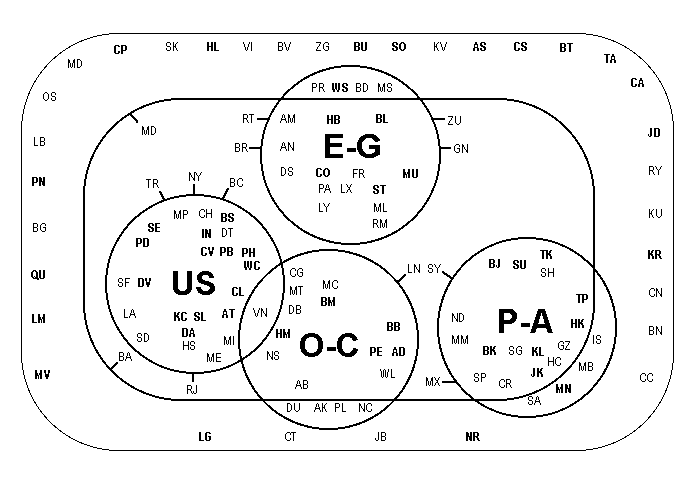
This is the final paper in a trilogy of arguments that cumulatively work towards a geography of globalization. The geography being constructed is a network configuration; the objects of concern are prime nodes in the contemporary world economy, the cities. The basic argument follows Sassen (1991) and Castells (1996) in the identification of a world city network within a global space of flows. Based upon the enabling technologies of combining computers with communications, world cities have taken the traditional service role of cities into a global scale of operation to provide a 'skeletal' structure for globalization. It is a description of this structure that is presented in this third paper. The first paper in the series (Taylor, 2001) provides a precise specification of the world city network. Although there has been much reference in the literature to concepts such as 'global network of cities' actual specification has been lacking. By identifying the world city network as an interlocking network with three levels - network, nodes (cities), and sub-nodes (global service firms) - a specification has been derived in which the firms are the major creators of the world city network. Firms 'interlock' cities through their office networks that are perforce worldwide to service global corporations with a branded seamless service. The specification consists of a basic city-firm matrix of 'service values' provided by each firm in each city from which are derived inter-city matrices of interlocking connections. The second paper in the series (Taylor, Catalano and Walker, 2001) describes how we have operationalised the specification through measurement of the world city network for the year 2000. Although there has been reference to much quantitative data in the literature, this has normally been used to rank cities in importance without any attempt to consider connections between cities. We tackle this empirical deficit in three stages. First, we have gathered information on the sizes and extra-locational functions of offices of 100 global service firms across 316 cities. Second, this multifarious information is converted into 'service values' - the importance of a city within a firm's office network - ranging from 0 to 5. Third, these data are used to derive measures of inter-locking connectivity between cities providing an index of global network connectivity for comparing the positions of cities within the world city network. In this third paper we take these data and begin analysis of the world city network. The data we use includes all 100 firms and the 123 highest connected cities. We do not use all cities because the data matrix becomes increasingly sparse (i.e. most firms score 0 (no presence) in a city) with smaller connectivities and thus becomes increasingly unsuitable for analysis. The 123 cities included all have a global connectivity of at least one fifth of the most connected city (London). Obviously this is an arbitrary cut off point, it has been chosen because it still provides us with a large number of cities that are distributed across all parts of the settled world. To reprise the "GaWC 100" firms: these are advanced producer service firms (18 accountancy, 15 advertising, 23 banking/finance, 11 insurance, 16 law and 7 management consultancy) that have offices in at least 15 different cities and with presences in each of northern America, western Europe and Pacific Asia. The latter requirement is to ensure we deal with not just large firms with many offices but that, in addition, they have global locational strategies. The multivariate approach we use to analyse this 123 x 100 data matrix is principal components analysis.1 In addition to the empirical aim of describing the basic configuration of the world city network, this paper has a methodological purpose. We adopt an exploratory approach to the data analysis using a series of principal components analyses producing multiple solutions. Confronted with a data matrix as large as this one, we do not expect to find simple definitive patterns and therefore the starting point should be an exploration to find different patterns within the complexity of the data. The first section below explains why principal components analysis is an ideal exploratory tool. The remainder of the paper then follows a route through the data matrix in which we focus on three stopping off points. The second section looks at a 2-component solution as 'the first cut', the third section proposes a 5-component solution as the 'prime structure' in the data, and the fourth section considers solutions 'below' the primary structure with particular attention given to a 10-component solution. In the conclusion we address both purposes of the paper: methodologically we consider the meaning of our exploration metaphor, and empirically we speculate on the nature of the globalization processes that could have created the configurations our analyses reveal. BEYOND PARSIMONY: PRINCIPAL COMPONENTS ANALYSIS AS A TOOL OF DATA EXPLORATIONExploratory data analysis is usually limited to univariate or bivariate situations where patterns of data can be visually displayed. Obviously such an approach is not directly possible in a large multivariate context. Simple visual presentations of the data remain an aim but their production has to be indirect following a deal of data manipulation. Principal components analysis is one of the factor-analytic family of multivariate techniques. These techniques are used to define the pattern of independent sources of variation in a data matrix. As such they are a popular means of producing parsimonious description of large and complex sets of data. In a previous paper we have used this parsimony argument for the use of this approach (Taylor and Walker, 2001). A good indication that this has become a standard argument for using a factor analysis is that in SPSS the family of techniques is reached by clicking on the "Data Reduction" button. However, in the classic social science text on factor analysis by Rummel (1970) a much wider range of uses is discussed. He identifies ten different 'design goals' for these techniques (Figure 8-1, p. 182) one of which is to 'explore'. This is the approach we adopt here but unfortunately exploratory analysis is not followed up at all in his otherwise comprehensive text. We attempt an initial rectification of this oversight here. Most statistical analyses, whether multivariate or not, are designed to provide an answer to a question. Answers range from averages (of frequency distributions) to gradients (of scatter plots) to clustering hierarchies (from data matrices) and in every case the research is carefully arranged to provide a 'best fit' answer to a research question.2 It is this idea of requiring a definitive answer that we elude in the research design we develop. The factor analytic family of techniques has always been vulnerable to criticism from those looking for the one and only answer in their data. Researchers carrying out factor analyses find themselves having to make more 'subjective' decisions than is normal for a quantitative analysis. This is because the method involves several 'sources of uncertainty' (Rummel, 1970, 349). Prominent among these is the number of factors to extract and rotate.3 Choosing different numbers of factors produces different results - alternative answers to the same question - and there is no agreed way to decide how many is required. Rummel (1970, 349) translates this uncertainty into "the Factor Number Problem" and devotes a whole chapter to how to decide 'the best number of factors' (p. 351, 367). Unable to provide a solution to the problem he concludes by admitting that the end result of his discussion has been to make the reader feel 'more confused' (p. 367) than before! We take a different track, rather than uncertainty being a problem we look at it positively. Creating many alternative results provides a means for exploring a set of data. Instead of searching for the 'best number', we consider all relevant numbers of factors. This 'multiple-number' design allows for comparison of results over a range of levels of 'data reduction'. In this way we uncover different sources of independent variation at different levels but we also see the similarities in patterns over different levels. The latter indicates the robustness of some factor patterns. Of course, this approach does not mean that we treat all solutions as being of equal relevance: exploration is all about evaluating the salience of different results using different numbers of factors. We know of no use of factor analysis in this exploratory manner so that the analyses below are presently tentatively as a methodological innovation for understanding large data matrices. The actual research design consists of 13 principal components analyses of the100 x 123 city-firm data matrix. The number of components extracted range from 2 to 14 wherein every solution has all components with at least one loading (interpretable as the correlation between a component and a variable) above 0.4. All these results are based upon varimax rotation to provide distinctive patterns of variation. The cities are treated as the 'variables' (i.e. Q-mode analysis) so that the sources of variation delineated are clusters of cities correlated in terms of similarities in their profiles of service values across firms. Our analytical route through the matrix is from most to least data reduction. THE FIRST CUT: DICHOTOMISING THE DATAThe simplest principal components analysis consists of rotating two components to find the most basic sources of variation in the data. This is to dichotomise the data into two broad clusters of cities with distinctively different profiles of firms. In fact because we only allocate cities to components where they have a loading of above 0.4 this produces a third group of unallocated cities. This exercise produces a first component of 66 cities, a second component of 38 cities, and leaves 19 cities unallocated. The specific results of the two-component analysis are shown in Table 1 and Figure 1. It is instructive to begin with the unallocated cities. Although a rather motley crew covering all parts of the world there is one notable feature of this group: it encompasses many major world cities. As well as London, New York and Tokyo, this group of 19 cities includes Chicago, Frankfurt, Singapore, Sydney and Zurich. Even where major cities are allocated to the components these are in the lowest category of loading (Hong Kong, Paris and Brussels in Component I, Toronto, Los Angeles and Washington in Component II). In complete contrast the upper reaches of both components are replete with the relatively minor cities within our 123. We interpret both components as clusters of what are sometimes termed 'wannabe world cities' (Short et al., 2000), important cities in their own right but outside the usual roster designated in world or global terms. Their generic name derives from the fact that such cities invariably have policies helping them strive for world city status. Labelling these two wannabe categories is quite straightforward. Component I is made up of cities from what used to be called the 'third world' plus eastern European cities and some more peripherally located cities in western Europe, notably in the far south (Mediterranean and Iberian cities) and far north (Scandinavian cities).4 Hence the designation Outer Wannabes. Contrariwise, Component II is dominated by relatively minor US cities plus the 'second cities' in western European countries (Manchester and Birmingham (both claim UK second city status), Barcelona, Lyons, Rome and Rotterdam) and second cities in selected associated countries (Montreal, Melbourne, Cape Town, Rio de Janeiro and Abu Dhabi). Clearly these are Inner Wannabes. This basic geographical dichotomy is clearly seen in Figure 1 where the first component straddles most of the world and the second component is concentrated in the 'old core', to use world-systems terminology. These are two distinctive policy worlds. For outer wannabes, rising up the ranks of world cities is primarily a 'development' issue, attracting global capital to become more central in the world city network. For inner wannabes rising in world city status is about changing the nature of national city hierarchies in order to come out of the shadow of a dominant local world city. We have previously suggested New York casts its 'world city shadow' over all other US cities (Beaverstock et al., 2000) and clearly London plays a similar role in the UK (Taylor, 1997). What does a clustering of cities into a principal component mean in terms of this data? The components are derived from the pattern of correlations between cities. Thus two cities loading high on the same component will share similarities in the service firms each house and in the 'service values' those firms give to each city. Thus components are clusters of cities with similar profiles of service provision across firms. The two components in this first cut therefore identify one cluster of cities with service firms relatively well represented beyond the 'old core', and another with service firms relatively more concentrated within the 'old core' itself. However such a simple division does not easily encompass the more important world cities. Remember all cities in the data have global strategies: those with an 'old core' bias will still need to have offices in the more important 'outer world cities', and those with a bias outside the 'old core' will still have offices in the more important 'inner world cities'. In addition these clusters of cities can be interpreted as indicators of sub-networks based upon flows (of information, of data, of orders) within firms' office networks. Given that firms pursue 'seamless service' for their clients, intra-firm connections should be larger than inter-firm connections within sectors. In short, principal components as clusters of cities describe configurations of the world city network. Finally it should be noted that in a usual factor analysis research design, these two-component results would normally be overlooked since in large complex data sets it is highly unlikely that the 'best' solution would have only two dimensions. However in our exploratory mode we have uncovered an interesting 'first cut' of the data which, as we shall see, will continue to have resonance in later analyses. Furthermore this use of a principal components dichotomy is more flexible in nature than alternative approaches to dividing the cities into two main groups. The multivariate design that is usually used to dichotomise a large data set is the first step in a hierarchical division analysis. But such divisions into two groups are highly rigid in two senses. First, all cases are allocated in a strict taxonomic manner, in contrast our result provide 'fuzzy groups' with both some overlap and recognition of non-membership. Second, once the hierarchical division continues though further steps in the analysis, cases remain in their initial half of the data so that the initial dichotomy limits the composition of groups at all subsequent hierarchical levels. This will not be the case with our exploratory factor analysis research design because each analysis at each level is an independent principal components analysis, uninfluenced by any previous analysis. THE PRIMARY STRUCTURE IN THE DATAAlthough we look at 13 different principal components analyses we have made the point that this does not mean that all are considered to be of equal salience in understanding the data. In this section we focus on the 5-components solution which we consider to be the most interesting of all the solutions. We interpret it as revealing the primary structure of the data for the following two reasons. First, it produces a reasonably balanced pattern of components in numerical terms (Table 2). Each component has at least five cities with high loadings (over 0.6) and each has a sizeable total of cities in its cluster (the two smallest components IV and V have 18 and 17 cities respectively). There are no such distinct and large components in solutions with more than five components. For instance the extra component in the 6-component solution has no loadings over 0.6 and 7 of its 10 cities have loadings below 0.5. Second, the 5-component solution produces a structure that is very easily interpreted. Thus as well as the numerical balance, these results provide a clear geographical meaning to the way our world of cities is divided. Clearly we are not proscribing further components with new patterns of cities, these will be goals for further exploration, but we are saying that this particular solution appears to evince what may be reasonably called a primary structure of the data. As such we will consider these results in greatest detail. To aid in interpreting the components in Table 2, Table 3 has been constructed by cross-tabulating the 5-components solution with the 2-components one. Where a city appears in two columns in Table 2, it is distributed in Table 3 on the basis of its highest loading. Table 3 shows that Components I and I in the 5-component solution are directly derived from the first cut solution: 37 out of 39 and 22 of 23 cities transfer directly across solutions. Inspection of these cities in Table 2 reveals that the new Component I is the Outer Wannabes shorn of Pacific Asian cities; we call it simply Outer Cities here. The new Component II is the Inner Wannabes shorn of non-US cities; we call it simply US Cities. Figure 2 shows their new contrasting geographies, Component II is the most concentrated cluster of cities, Component I is the opposite spread across the world everywhere except in the three main globalization arenas of northern America, western Europe and Pacific Asia. The latter region is represented by Component III as Pacific Asian Cities5 in Table 2. Nearly all of these cities were originally part of the Outer Wannabe cluster (Table 3): Pacific Asian Cities represent a split from the Outer Wannabes. This analytical emergence parallels the historical emergence of this region out of the 'third world' to produce contemporary globalization. But it is more than this, in the 5-component solution there is a reordering of cities so that the region's major cities are more prominent: Tokyo and Singapore are added from unallocated cities and Hong Kong rises two levels in loadings in comparison with the 2-component analysis. The result is a second concentrated cluster in Figure 2. The final two components in Table 2 are fresh creations. Component IV brings together European cities headed in particular by German cities. It combines eastern European cities that were Outer Wannabes with German cities and other western European cities that were not allocated in the 2-component solution. We have labelled this Euro-German Cities. In Figure 2 this is the third concentrated cluster. Component V is different in having a world-wide distribution in Figure 2. Straddling Australia, Britain and Canada, Component V is labelled Old Commonwealth Cities6 (Table 2). Although not geographically concentrated, this is clearly a distinct politico-cultural cluster of cities. In the 5-component solution there are 12 cities still not allocation and there are another 13 cities that are allocated to two different components. In Table 4 the unattached 12 are listed under the component on which they load highest. By definition these are relatively small loadings so that interpretation is subsequently limited. Certainly the new allocations to components III (Pacific Asia) and IV (Euro-German) seem sensible but this is not the case for the other three components. In fact the most notable feature of this table is the confirmation of how 'un-American' New York is: it is more like the minor outer cities than its fellow-national cities! The set of13 doubly-loaded cities, which we call hybrid cities, are more interesting. These are shown in Table 5 where all but one hybrid city features the Outer cluster. Hybrid cities are in between being part of the amorphous collection of relatively minor cities and being part of a more distinctive cluster. This relation is shown diagrammatically in Figure 3 where the wannabe Outer Cities encompass the world but the distinctive clusters of US Cities, Pacific Asian Cities and Old Commonwealth Cities combine wannabe and major world cities in coherent regional and politico-cultural inner configurations. This diagram is our representation of the primary structure of the data. To begin to understand the processes behind the production of this structure we need to consider the firms, who are, in this specification of the world city network, its creators. We do this by computing the component scores for the 100 firms. Like loadings, scores indicate importance (of cases rather than variables) with respect to a given component. Relatively high scores (we use a threshold of 1.5) are shown in Table 6. These results are as distinctive as the loadings we have previously interpreted. Outer Cities are associated solely with accountancy and advertising firms, precisely the sectors in which firms have the widest range of offices. US Cities are associated with several sectors but the firms have two characteristics, large size and US headquarters. Pacific Asian and Euro-German Cities are similarly associated with 'regional' headquartered firms, in Tokyo and German cities respectively, but the emphasis is very much on one sector, banking/finance. The Old Commonwealth Cities are associated with a range of sectors, like US Cities, in this case with London headquartered firms notably in insurance and accountancy being prominent. This all suggests that contemporary globalization has a structure resulting from geographical (physical and politico-cultural) diffusion from the prime globalization arenas (northern America, western Europe and Pacific Asia) and that these regional (and politico-cultural) imprints remain very evident. The expansion of successful firms in Tokyo, London, USA (largely New York) and Germany (largely Frankfurt) has outgrown local, regional and cultural boundaries to coalesce in contemporary globalization. Beyond these imprints there is a veneer of a more even globalization produced by firms in the two sectors that globalized early and widely across the world. It is accountancy and advertising firms, in particular,that have made the world city network more than an enhanced trilateral regional configuration. But the primary structure remains founded on the three globalization arenas with just the Old Commonwealth Cities providing a slightly different historical twist to the story. BELOW THE PRIME: SECONDARY STRUCTURESIn this section we have chosen to focus initially upon the 10-component solution to illustrate further clusters of cities that we shall term secondary structures in the data (Table 7). This solution shows clearly three new city clusters and also illustrates the degeneration into very weak components as the number of components increases. In addition it supports the previous identification of a primary structure as a simple comparison between Table 2 and the first five components in Table 7 reveals. Both sets of five components are very similar and in Table 7 the importance of components immediately drops after Component V. Although this shows the primary structure to be robust the two sets of five components are not exactly the same. As well as a different order of extraction (IV and V are transposed between solutions), two of the prime factors alter slightly with extraction of secondary structures. This reflects the autonomous nature of different analyses in this exploratory strategy and reminds us that the primary structure we have identified defines the most important, relatively robust, components but it should not be interpreted as the 'correct' answer from the 'right' analysis. This will become clear as we interpret secondary structures by taking each new component in turn. Component VI has no high loadings but nevertheless includes ten cities in Table 7. Since the cities are relatively important world cities and seven are from North and South America we label this component Larger Americas' Cities. This necessitates re-labelling (relative to the primary structure) the USA component as Minor US Cities. Similarly Component VII has an altering effect on the European component from the primary structure. We label this next component Western Europe Cities noting that it includes no German cities; these remain in the larger German-dominated European component. However, the latter now becomes a narrower component labelled German-East European Cities. Component VII is a rather minor component which we label Indian Cities (with Guangzhou as a hybrid case with Pacific Asian Cities). These cities come from the primary structure Outer Cities but this secondary structure is too weak to effect a substantial alteration to the original in this case. Component IX is a very minor dimension of common variation incorporating just four cities that are each rather minor but with a banking speciality: our label is Minor Financial Centres. This interpretation is supported by cities with loadings just below the 0.4 threshold for appearing in Table 7: Hamilton (Bermuda), Lyons and Geneva. Finally Component X looks very insignificant with just a single low loading but again looking below the 0.4 threshold suggests this Stockholm component might represent an incipient Scandinavian Cities cluster: Copenhagen, Oslo, Helsinki and Amsterdam (with its traditional Baltic links) are just below the threshold. However having to search through relatively low loadings to make sense of the last two components does illustrate that these are very minor patterns of common variation; we consider just the initial three new components as representing secondary structures. The three secondary structures are not necessarily best portrayed in the 10-component solution. Looking through other solutions we have selected similar components that have a tighter structure in Table 8. For instance, the rather 'loose' (no high loadings) Americas component is more clearly specified as Major Latin American Cities in component 6 of the 6-components solution.7 With US cities not loading on this version, the US Cities cluster is retained. Note however that minor Latin American Cities remain in the Outer Cities cluster suggesting a clear size differential among cities of this region. Similarly Component VII of the 7-components solution provides a slightly more precise specification of Indian Cities with New Delhi becoming more important. However, Mumbai still remains in the Pacific Asia cluster suggesting another size differential between cities of a region although this time it is the smaller cities that define the regional cluster. Finally the Western European Cities are defined more clearly by component VII in the 9-component solution which includes 9 cities including one German city, Cologne suggesting this city is less connected to Eastern European cities than other German cities. CONCLUSION: A ROUTE THROUGH THE WORLD CITY NETWORKIn describing our research design we have used the metaphor of exploration. We think this has shown itself to be a good metaphor for the way it encompasses our methodological purpose. To explore is to venture into unknown territory where there is no room for rigid thinking; a flexible approach is a necessity. Because of the inherent 'uncertainties' in the application of the factor analytic family of techniques, their analyses can be adapted to a simple exploratory research design that is immensely flexible. Hence we have been able to illustrate how principal components analysis can be used as a tool for exploring a large complex data matrix. Without searching for definitive answers, we have uncovered some of the basic patterns that constitute our data. The closest we come to a traditional analytical 'answer' is in the identification of a 'primary structure' in the data. However, it should be pointed out that this was not an aim in embarking on the exploration. This primary structure was encountered en route through the data. In applications of this research design with other data there may well be no such primary structure. There are, of course, many multivariate techniques that can be employed to analyse large data matrices but we think that employing principal components analysis as an exploratory tool is arguably the most fruitful way to begin an understanding. We believe our results are a justification for this assertion. We do not produce neat findings. There are overlaps between clusters of cities, some cities are not allocated, and the content of clusters alters through different analyses. There is definitely no simple hierarchy of world cities. Nevertheless we do finish up with a reasonable understanding of the structure of the data. This can be summarised as a primary pattern of five common sources of variation, three smaller secondary structures and two possible minor patterns with the global cities of London and New York outside all structures. This is a new geography of globalization as indicated by the configuration of world cities that was promised at the outset. It is offered as a rare research output: a sound empirical depiction of globalization based as it is on a precise specification of the world city network and a careful measurement of the global strategies of 100 major service firms. ACKNOWLEDGEMENTThis research was carried out as part of the ESRC project "World City Network Formation in a Space of Flows" (R000223210). REFERENCESBEAVERSTOCK, J. V., SMITH, R. G., TAYLOR, P. J. (2000) World-city network: a new meta geography? Annals, Association of American Geographers, 90, pp. 123-34 CASTELLS, M, The Rise of Network Society. Oxford: Blackwell RUMMEL, R. J. (1970) Applied Factor Analysis. Evanston, IL: Northwestern University Press SASSEN, S. (1991) The Global City. Princeton, NJ: Princeton University Press SHORT, J. R., BREITBACH, C., BUCKMAN. S., ESSEX, J. (2000) From world cities to gateway cities, City. 4, pp. 317-40 TAYLOR, P. J. (2001) Specification of the world city network, Geographical Analysis, 33, pp. 181-94 TAYLOR, P. J. and HOYLER, M. (2000) The spatial order of European cities under conditions of contemporary globalization, Tijdschrift voor Economische en Sociale Geografie, 91, pp. 176-89 TAYLOR, P. J. and WALKER, D. R. F. (2001) "World cities: a first multivariate analysis of their service complexes" Urban Studies 38 23-47 TAYLOR, P. J., CATALANO, G., WALKER, D. R. F. (2001) "Measurement of the world city network" GaWC Research Bulletin 43 TAYLOR, P. J., DOEL, M. A., HOYLER, M., WALKER, D. R. F., BEAVERSTOCK, J. V. (2000) "World cities in the Pacific Rim: a new global test of regional coherence" Singapore Journal of Tropical Geography 34 33-45 NOTES1. In a previous paper (Taylor and Walker, 2001), we employed a principal components analysis on a similar data matrix comprising 55 cities and 46 service firms with service values ranging from 0 to 3. This was a preliminary experimental data set derived from a different research project that was primarily concerned with London. As well as the new data employed here being more comprehensive (68 more cities, 2 more sectors and 54 more firms), there is a better balance of service firms: in hindsight the first data incorporated too many law firms (with 16, the largest sector represented). Obviously with such major differences exact parallels with the new analysis cannot be expected but similarities between analyses will be pointed out in footnotes below. There were also regional data matrices derived from the London project and results from their analyses in Taylor and Hoyler (2000) and Taylor et al. (2000) will also be compared with the new global analysis as appropriate. 2. This is effectively what we did in Taylor and Walker (2001) by presenting the solution with the most interpretable components. 3. The first source of uncertainty that Rummel (1970, chapter 14) identifies is in selection from among a wide range of factor techniques which themselves can be based upon different models (chapter 5) and rotations (chapter 6). For the exploratory purposes pursued here we do not use this variation in technique, rather we employ the most basic factor analytic method: a principal components analysis with principal axis extraction and varimax rotation. In the first stage of looking at the configuration of the data it seems to us that differences in the number of possible common patterns of variation is the crucial path to explore. 4. This European part of the Outer Wannabes is similar to the Outer Triangle of Cities in Taylor and Hoyler (2000, 183). 5. A similar cluster is identified in both Taylor and Walker (2001, 39) featuring Minor Pacific Asian Cities and Taylor et al. (2000, ***). 6. This was also identified in Taylor et al. (2000). 7. A similar component is to be found in Taylor and Walker (2001, 39) as Major Transnational and Latin American Cities. Table 1: Cities allocated to two components
Cities are ranked by loadings in each category * indicates second highest loading for a city Cities unallocated to two components:
Table 2: Cities allocated to five components (loadings above .4)
Table 3: Cross-tabulation of cities for 2 and 5 components
Table 4: Highest loadings of unallocated cities to five components
Table 5: Hybrid Cities (cities with two loadings above .4) with five components
Table 6: Firms with the highest scores on five components (firms are ranked by scores in each cell)
Accountancy, Advertising, BANKING/FINANCE, Insurance, Law, Management Consultancy.
Table 7: Cities allocated to 10 components
Table 8: Cities allocated to specific factors in different analyses
Figure 1: Two clusters of cities
This cartogram places cities in their approximate relative geographical positions. The codes for cities are: AB Abu Dubai; AD Adelaide; AK Auckland; AM Amsterdam; AS Athens; AT Atlanta; AN Antwerp; BA Buenos Aires; BB Brisbane; BC Barcelona; BD Budapest; BG Bogota; BJ Beijing; BK Bangkok; BL Berlin; BM Birmingham; BN Bangalore; BR Brussels; BS Boston; BT Beirut; BU Bucharest; BV Bratislava; CA Cairo; CC Calcutta; CG Calgary; CH Chicago; CL Charlotte; CN Chennai; CO Cologne; CP Copenhagen; CR Caracas; CS Casablanca; CT Cape Town; CV Cleveland; DA Dallas; DB Dublin; DS Dusseldorf; DT Detroit; DU Dubai; DV Denver; FR Frankfurt; GN Geneva; GZ Guangzhou; HB Hamburg; HC Ho Chi Minh City; HK Hong Kong; HL Helsinki; HM Hamilton(Bermuda); HS Houston; IN Indianapolis; IS Istanbul; JB Johannesburg; JD Jeddah; JK Jakarta; KC Kansas City; KL Kuala Lumpur; KR Karachi; KU Kuwait; KV Kiev; LA Los Angeles; LB Lisbon; LG Lagos; LM Lima; LN London; LX Luxembourg; LY Lyons; MB Mumbai; MC Manchester; MD Madrid; ME Melbourne; MI Miami; ML Milan; MM Manama; MN Manila; MP Minneapolis; MS Moscow; MT Montreal; MU Munich; MV Montevideo; MX Mexico City; NC Nicosia; ND New Delhi; NR Nairobi; NS Nassau; NY New York; OS Oslo; PA Paris; PB Pittsburg; PD Portland; PE Perth; PH Philadelphia; PN Panama City; PR Prague; QU Quito; RJ Rio de Janeiro; RM Rome; RT Rotterdam; RY Riyadh; SA Santiago; SD San Diego; SE Seattle; SF San Francisco; SG Singapore; SH Shanghai; SK Stockholm; SL St Louis; SO Sofia; SP Sao Paulo; ST Stuttgart; SU Seoul; SY Sydney; TA Tel Aviv; TP Taipei; TR Toronto; VI Vienna; VN Vancouver; WC Washington DC; WL Wellington; WS Warsaw; ZG Zagreb; ZU Zurich
Figure 2: Five clusters of cities
For city codes see Figure 1
Figure 3: The primary structure of the world city network
Edited and posted on the web on 12th July 2001; last update 22nd April 2002 Note: This Research Bulletin has been published in Urban Studies, 39 (13), (2002), 2377-2394 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||