GaWC Research Bulletin 308 |
|
|
|
This Research Bulletin has been published in Journal of Urban Technology, 18 (1), (2011), 73-92, under the title 'Searching for Cyberspace: The Position of Major Cities in the Information Age'. doi:10.1080/10630732.2011.578410 Please refer to the published version when quoting the paper.
IntroductionRanking Cities: From Attributes to FlowsFrom Mark Jefferson’s study of primate cities in the 1930s, through Kingsley Davis’ work on millionaire cities in the 1950s, to current developments in analyzing digital flows between cities, we can trace a rich genealogy of scholarly interest in classifying and ranking the cities of the world. Early studies took population as the definitive factor in determining urban hierarchy. And although population size remains an important dimension in terms of economics, quality of life and sustainability, its inadequacy, alone, for defining “importance” is clear; more than half of the world’s 30 largest cities are located in Asia, yet few of these rank among the commercial, political and cultural centers of gravity in the global city system (Williams and Brunn 2004). Thus, in the second half of the twentieth century, sociologists, economic geographers and economists introduced a number of other criteria to identify the most important cities within a region, or at the global scale, in terms of commerce, politics and culture, such as: headquarters or major corporations; banking and financial institutions; quantity of NGOs, etc.) (e.g., Hall 1966, Friedmann 1986, Knox 1994). The quickening and deepening connections between places, that is, flows held to be characteristic of the contemporary globalizing world, called for and calls for new ways of apprehending the relative importance of cities in an “Information Age” (Castells 1996). In his seminal work, Manuel Castells (1996) argues that qualitative changes in the nature of contemporary society necessitate a “new spatial logic,” that is, one based on networks of informational flows: “ flows of technology, flows of organizational interaction, flows of images, sounds and symbols” (Castells 2000, p. 442). According to this argument, the present Information Age was preceded by an Industrial Age for which physical space was an appropriate and necessary organizing logic for a world in which synchronicity in time required co-presence in space. Physical proximity and face-to-face interaction were definitive of industrial society. But, recent developments in high speed transportation over long distances, and, more dramatically, the rise, diffusion and uses of Information Communication Technologies (ICTs) have fundamentally reconfigured previously taken-for-granted relationships between time and space. At the most basic level, ICTs entail a decoupling of simultaneity in time from contiguity in space: in the Information Age simultaneity no longer relies on physical contiguity (Sheller and Urry 2006). Therefore, a careful and critical reading of Castells (1996) suggests that the global urban system should be apprehended not as a space of places, that is, the historically rooted spatial organization of common experience with its implicit fixity in absolute space and stasis with respect to time, but as a space of flows, acknowledging the multiple, overlapping spatialities of information in material and “virtual” spaces and their continuous reconfiguration through time. Decentering place as the site of meaning, in the sense that places constituting reservoirs or stores of information, implies a methodological shift in our information measurement rubric. Instead of studying cities as entities with attributes (characteristics of areas), we study cities as comprising sets of relationships (characteristics of relationships between areas). The challenge of how to operationalize this prioritization of flows and relationality over place (entities) and attributes is one that has often been recognized, but not addressed (Derudder 2006). That is, while theoretical influential work has emphasized, the need for a relational approach to the global urban system, empirical elaboration has been lacking. In this regard, we flag Friedmann (1986), Sassen (1991), and Castells (1996) as high profile advocates for using “flow” (or relational) data in the study of the global urban system. The absence of empirical elaboration that we note here has not gone unnoticed in previous studies. Indeed, Taylor (1997) describes it as the “data deficiency problem”, Beaverstock et al. (2000a) as the “Achilles heel of the literature”, and Short et al. (1996) as “the dirty little secret of world cities research”. Friedmann (1995, p. 24) goes further, suggesting that:
This frequently-raised problem of suitable data has only recently spurred a re-energized focus in the transnational urban network literature on specifying empirically the nature of inter-city connectivities (Derudder 2006). Leading examples of these new, empirical approaches include the outcomes from the Globalization and World Cities group (GaWC) on corporate organization in advanced producer service firms (e.g., Taylor 2001, 2004), along with infrastructure-based studies on “global reach” such as Internet infrastructure (e.g., Malecki 2002, Rutherford et al. 2004) and airline networks (e.g., Smith and Timberlake 2001, Zook and Brunn 2006). These are clearly important studies that address in some detail various dimensions of the physical connections between cities in the global urban system. While these studies are useful and are valuable additions to the global urban systems literature, we would argue that there remains a lack of up-to-date and updatable measures of information flows that acknowledge that these flows are intangible and not simply embodied in people (in the case of airline network analysis) or places (in the case of studies that focus on the physical, enabling infrastructure of electronic communications). Thus despite a seemingly widespread consciousness of the importance of information “itself” in the ICT-driven world, analyses on the relative position of cities in respect of this Information World are exceptional in urban and social research. Partially bucking this trend are studies that use content analysis to analyze news sources (e.g., Pred 1980, Beaverstock et al. 2000b) or analyses of conference proceedings in respect of specific topics through time. Beaverstock et al. suggest, for instance, that the analysis of a daily business newspaper provides a way out of this lack of suitable data. A (world) city's newspaper provides, according to Beaverstock et al. (2000b, p. 49), “a continuous source of information on what a given editor thinks are the salient news stories of the day for a given readership, the city's business community.” Thus, “by recording place mentions in a sample of business news stories one can derive a surrogate measure of a city's external relations.” However, w hat is desirable and urgently required, particularly in times of global crises are up-to-date and real-time measures of information about cities, and informational flows between cities. The key point here is that currently we have access to unprecedented volumes of relevant information: the WWW being the most prominent and obvious example which, with the rise of new ICTs, is a vast and valuable information source for monitoring changes in urban relations as well as for a quantitative estimate of business salience. Currently almost one in four of the world’s population now makes some use of the World Wide Web (internetworldstats.com 2009). This observation is just one of the endless number of possible illustrations of the taken-for-granted vastness of the Web as an informational database with great (and global) reach. Correspondingly, Web search engines such as Google, Yahoo, Bing, and AltaVista indexes billions of Web pages—numbers that grow by continuously creating, to all intents and purposes, seemingly inexhaustible databases. These databases are both vast and timely, two characteristics which, we argue, potentially make critical and judicious analysis of their content an exciting and rich source of insights into the cyberspaces of the global urban networks. In this paper, we have two central aims, one methodological, the other substantive. Methodologically, we introduce and argue for the Google database (i.e. the leading and de facto standard Web search engine (Marketshare.hitslink.com 2009, GlobalStats 2009)) as an appropriate dataset for examining the growing importance of knowledge as a raison d’être for a city’s economic ranking on national, regional, and global scales. Second, we use this dataset to derive real-time informational rankings of the world’s largest cities in respect of two prominent current issues global in scope: the global financial crisis, and global climate change. The remainder of the paper is in four sections. In section II, we set out, with references to an examination of the existing literature on the informational connectedness of the world’s cities, especially the importance of monitoring cities and their cyberspaces in real-time. Next, in section III, we introduce and discuss in detail the methodological arguments for using Google as the source of real-time informational rankings, and introduce our measures of “importance” in relation to interconnectedness and information in terms of the global financial crisis and global climate change. In this section we discuss some of the problems and shortcomings with these methods, but also emphasize the opportunities and advantages of making use of these heretofore unavailable methods for monitoring cities in real-time. In section IV, we present some preliminary rankings for the largest 100 cities based on the methods introduced in section II. In this section we present: (i) city Global Financial Score (GFS) and Global Environmental Score (GES) rankings based on hyperlink volume, that is, the number of hyperlinks on selected topics; (ii) a content analysis of global financial data; and (iii) some preliminary analysis of the role of language. Finally, we reflect on the results and suggest some future directions for monitoring cities in real-time. CONCEPTUAL FRAMEWORKWhat Flows? Defining and Measuring Information Connection
Hillis (1998, p. 545) Although there exists a number of studies on information flows (see above), most of these studies have a narrow transportation-orientated focus. As Hillis (1998) suggests the material flows of people, products and objects are all-too-often substituted as proxies for the less tangible flows of information or knowledge. Often for understandable methodological reasons, researchers have tended to apprehend flows of information on the basis of its enabling infrastructure or its media of transmission (flows of books, magazines, letters, documents, bits, etc., rather than attempt to trace information “itself” (e.g., Mitchelson and Wheeler 1994). Examples in the recent world cities literature of this transportation-orientated focus are multifaceted (e.g., Malecki 2002, Rutherford et al. 2004, Choi et al. 2006). They analyze flows of bits--units of digital data--across space using what has been termed in Devriendt et al. (2008) a “cyberplace” (CP) approach, that is, one which traces out a very particular cyber geography of physical infrastructure and material connection. The analog between this spatially fixed infrastructure of network hubs and nodes on the one hand, and the global airline network of global cores, regional gateways, peripheral nodes, etc. on the other, is clear. As with airline transportation, digital data travel along more-or-less heavily trafficked but always predetermined routes, tracing out hierarchical networks of more-or-less integrated/interconnected places. These “network” analyses of information flows unveil the supposedly-unbounded and “new” virtual world as one underpinned by a familiar political-economic geography manifest in the uneven concentration of Internet “real estate” (Dodge and Shiode 2000, Hanley 2004), for example, Internet Service Providers (ISPs), servers, etc. The CP insight that the physical location of Internet infrastructural components underlies an apparently untethered space of flows thus provides a useful counterpoint to excited/excitable proclamations of a “borderless world” (Ohmae 1990 is a paradigmatic example). However, simultaneously, such a method also reproduces the “old” assumptions about the “contained” and material nature of information. Thus, if we want to know more about cities and their relative positions within the current globalized Information World, we need to study not only tangible informational infrastructure and its associated placed flows, but also the cyberspaces of cities in relation to information (Bakis 1993, Hillis 1998, Kellerman 2002). If information/knowledge is the key determinant of prosperity and the key driver of economic growth (Dutta and Mia 2007), questions around what and not just how knowledges flow between cities become central to the study of cities and city places within the global urban hierarchy. Our approach considers the ways in which cities are (re)constructed both as material spaces (of infrastructure, people and institutions) within a global information/knowledge economy—per the CP “network” literature—and as “hybrid places”, viz., the identities and experiences of which are mediated by ICTs (Paradiso 2003). The idea that “world cities are very much a product of the enabling technologies of telematics” is not a new one (Knox and Taylor 1995), but as noted above the empirical basis for such claims is limited (see Dodge and Shiode 2000, Dodge and Kitchin 2001, Devriendt et al. 2008). In other words, in a knowledge economy, there exists a need to apprehend the informational interconnections between cities of the world in ways that take into account the real-time and continuous production of urban places: that is, we need to consider, empirically, the ways in which knowledge is produced about and works to (re)produce urban places and their interconnections. The challenge comes in maintaining a healthy distance from claims of an unbounded, democratizing, placeless (etc.) “virtual” world, while at the same time arguing that the knowledge economy is not reducible to volumes of bits, nor the physical location of ICT infrastructure. We are aided in this task by the empirical insights of the “cyberspace” (CS) approach, as presented in Devriendt et al. (2008), the analysis of digital city-networks, and the theoretical insights of what Crutcher and Zook (2009) describe as “cyberscape”. The so-called cyberplace (CP) approach, characteristic of the transportation “network” analyses identified above, can be contrasted with the here-adopted cyberspace (CS) approach, that is, where the former (CP) makes use of a tangible infrastructure to analyze the “virtual” transnational linkages of cities located in absolute space and the latter (the CS approach) is concerned less with the materiality of the enabling infrastructure than with the material effects of information that takes on myriad, intangible forms as it is produced, disseminated, translated and consumed between and within places. Our interest is in identifying those information flows between places (per the CP approach), but also to analyze both qualitatively and quantitatively what and how much information flows about places (the CS approach). As Crutcher and Zook (2009) demonstrate, Web information is not simply channelled or transported immutably between locations; it does not neutrally represent an underlying material reality nor does it exist as an “informational cloud” (de Vries 2006, p. 3) floating above, and epistemologically and experientially discrete from, the materiality below on which it draws and to which it refers. Rather, as Crutcher and Zook’s (2009) concept of cyberscapes reminds us, information and representations of spaces (maps, photos, numerical data, etc.) are related in complex ways to the experience of place. In Dourish’s (2006) words: rather than “creating a distinct sphere of practice”, virtual worlds, “open up new forms of practice within the everyday world”. Any informational ranking of cities needs to be cognizant of these complex qualities and impacts of information. METHODA Massive, Global Knowledge Database
(Alderson and Beckfield 2004, p. 820) While virtually all studies on the importance of cities in the global economy begin by lamenting the lack of suitable comparative and relational data (e.g., Short et al. 1996, Beaverstock et al. 2000a, b, Smith and Timberlake 2001, Taylor 1997, 2004, Hall 2001, Alderson and Beckfield 2004, Zook and Brunn 2006, Derudder et al. 2007), we argue that this lamentation is no longer a critical issue in studies looking at the positions of cities in terms of information. Indeed, a core characteristic of the Information Age is precisely the unprecedented volumes of and access to information—the Web being the most prominent and obvious example. The number of Web sites is estimated to stand at around 232 million (April 2009), a huge and growing number representing a ten-fold increase since the end of 2000 (Netcraft 2009). Such a database, literally hundreds of billions of “pages”, represents a huge and thus far under-utilized source of data on the characteristics of and relationships between cities’ cyberspaces. We base our empirical analysis on information derived from the most popular search engine, Google. Google fast became and stands as the de facto standard search engine (Marketshare.hitslink.com 2009, GlobalStats 2009). Search engines use complex algorithms to respond to users’ key word queries with a ranking of relevant Web pages from their continuously updated databases. Google’s search algorithms--the behind-the-scenes rule sets that subject user input to a series of steps and then outputs the resultant SERPs (search engine results pages)--take into account more than two hundred “signals” in determining the order of returned search results. We know a lot about what Google values: that is, what characteristics of a Web page or other online document determine its importance. Incoming hyperlinks (from sources that are also ranked in terms of their importance) matter, as does content and, perhaps to some extent, ratings of “authority” based on popularity or the domain name. For example, educational sites, .edu and .ac.uk, and governmental sites, .gov might rank more highly than commercial domains). Google is still working on the “perfect search engine”, one that “understands exactly what you mean and gives you back exactly what you want” (Larry Page, founder)1. Until perfection is achieved, we use the Google search engine cautiously in our research, even as we suggest that if offers the largest (perhaps the only) index of textual information suitable for our purposes: continuously updated and timely. Hyperlinks have not been used much by geographers to examine urban linkages or to rank cities. We identify only three studies that have attempted to make use of hyperlink data in this context. First, Brunn (2003) uses hyperlinks to examine the linkages (volumes or flows) between four Eurasian cities: Moscow, Istanbul, Teheran, and Beijing. Next, Williams and Brunn (2004) map the linkages of the largest cities in Asia and categorize the most prominent search engine-derived information for 197 cities. And, most recently, Devriendt et al. (2008) use an analysis of hyperlink dyads to trace out a European inter-city informational networks. This study builds on and extends these earlier “hyperlink research” projects in three ways. First, we look at the 100 largest population cities on a global scale through an examination of hyperlink volume. Second, we examine these cities’ cyberspaces more specifically vis-à-vis global economic and global environmental criteria, that is, the current global financial crises and global climate change. Third, we examine the content of Web pages pertaining to each of the hundred cities in relation to both the economic and environmental issues. Our three-pronged approach allows us to quantify the informational connections between cities; compare the relative importance of key topics in/to cities, and specify and compare the dimensions of current events most prominently associated with each of the 100 cities. One shortcoming of the previous hyperlink studies is that there is not any critical reflection or discussion on the merits of using search engine data. While there are clearly great advantages to using the Google Search Engine (versus the “infrastructural” datasets to which we have referred)—especially size (over one trillion unique URLs trawled), and timeliness (the index is continuously updated by its distributed network of “spiders”)—some cautions are required. As one reads the world city classification literature, it becomes clear that there are substantial limitations, as well specific strengths, to any database used or any measure devised to rank individual cities. Thus these concerns are not a problem unique to Google data. Before proceeding with our analysis, it is important to address three specific potential “problems” with the present dataset: (i) ambivalent search terms; (ii) word order and temporality, and (iii) language. We also outline how these are addressed in the subsequent analysis. We consider the methodological implications of these three issues and, in the case of (ii) and (iii), identify not just challenges, but also major opportunities afforded by using the dataset. i) Ambivalent Search TermsAttempting to quantify inter-city relationships using dyadic hyperlink pairs can result in “unwanted”/irrelevant search results (see e.g., Williams and Brunn 2004 or Devriendt et al. 2008). For example, Devriendt et al. (2008) describe a European inter-city informational network by quantifying the links between pairs of cities. Understanding the informational connectivity between London and other European cities entails entering into the search engine “London” in conjunction with each other city name in turn: “London and Berlin”; “London and Brussels”; “London and Paris”. This latter search term, “London and Paris” returns, in addition to “relevant” Web pages, substantial numbers of Web pages (blogs, “news” sites, forums, etc.) referencing celebrity Paris Hilton and her visit to London. Other examples spring readily to mind: “Washington” may refer to the U.S. state, the first U.S. president, countless towns, cities, streets, people, apples, etc. throughout the world, as well as the “correct” Washington, D.C. In previous studies based purely on hyperlink/Web page volume, these ambiguities cause substantial distortions in the search results. Furthermore, it is all but impossible given the (literally) millions of Web pages involved to estimate the size of the distortion: how many of the c. 43 million results for “London and Paris” pertain only to London and Paris Hilton, and not London and Paris, France (or perhaps London, Paris, France and Paris Hilton together)? Since we are interested here in the content as well as the quantity of information, we are able to mitigate such effects related to ambivalent search terms as follows. Our mining of the Google database relates cities to information on specific topics, and this we minimize, if not remove entirely, the Paris Hilton effect. Adding the words “global financial crisis” to “London and Paris” eradicates the ambiguity as to which Paris we are referring and thus no longer returns (many) Hilton-related results. ii) Word Order and Temporality Searching for “Brussels and London” yields a different quantity of search results than does searching for “London and Brussels”. The 100x100 matrix of world cities and their hyperlink connections is therefore not symmetrical. The solution to this search engine quirk is to standardize results. Averaging the number of results for the two search terms provides a figure that does not systematically under/overestimate the “actual” volume. As we have discussed above, a great advantage of the Google search index is its timeliness. The database is continuously updated, second by second as spiders trawl for new, updated and defunct content. This timeliness has two main implications. In order to obtain “snapshot” data, we utilized a script to run our queries and extract search results synchronously. In this way, we avoided the potential bias inherent in performing different parts of the data acquisition hours or days apart. The timeliness of the search database has a second implication, however, viz., the potential to track information and connectedness through time. We are currently engaged in a year-long project to monitor the temporal change in city rankings in respect of our topical indicators. By using Google Trends, we are able to illustrate the fluctuating salience through time of the keywords used in our analysis. We suggest the ways in which time series data might be used.
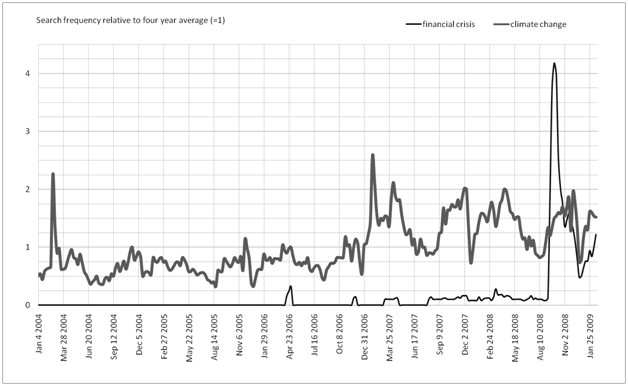
Figure 1: Google Trends – Search frequency values for “financial crisis” and “climate change”
Figure 1 illustrates fluctuations in the volume of Google searches pertaining to our two topics: global financial crisis and global climate change. In this graphic, weekly search volumes for each topic are represented by a search frequency value, via., an index in which the long-term (June 2004 to January 2009) weekly average volume is fixed at 1. Thus, for example, a search frequency of 4 represents a weekly search volume four times the magnitude of the long-term weekly average. The financial crisis trend line is based on search volume for “global financial crisis”, an amalgam of the two most popular financial crisis-related search terms over this period: “financial crisis” and “global economic crisis”. The climate change trend line uses search volume data for the two most frequent climate change related search terms: “global climate change” and “global warming”. In each case, we used the Google Insights service to identify the two most frequently searched keyword terms related to each topic. Search volume for climate change information fluctuates during this 103 month period, reaching a peak in the week beginning January 28 th 2007, the week that the IPCC (International Panel on Climate Change) report Executive Summary hit the international news media. Peaks and troughs in search frequency for climate change information can/could be correlated in more detail with the ebb and flow of news stories, political campaigns, published scientific data, and so forth. The most popular financial crisis-related queries for the years 2004, 2005, 2006 and 2007 were “Asian financial crisis”, “Asian crisis”, and related terms. During 2008, however, the term “Asian financial crisis” is relegated to the ninth most frequently used search term; it was replaced by eight financial crisis-related search terms referring explicitly to the present global crisis, including the terms “global crisis” and “global financial crisis”, with, respectively, 3.5 and 4 times their long-term average number of searches being made during 2008. The Google Trends data references the volume of searches rather than quantity of search results. Further, we do not have detailed information about where searches are made from (where users are located) or where users are. What these dramatic fluctuations show, however, is the extent to which interest in and information about core issues changes through time. We can speculate that, related to current events (for example, political speeches and market data in terms of the financial crisis) have a spatial component, that is, different cities will exhibit differential rates of change in terms of their “rank” in respect of informational criteria. iii) LanguageAn obvious concern about any attempt to classify cities in terms of (largely) textual information, is certain to raise the question of language. In our work, city names are spelled in English. Further, adding the phrases “global financial crisis” or “global climate change” and searching via Google.com (the US/international version of Google) removes any doubt that our analysis pertains to the English language Web. Two comments are in order here. It is axiomatic, that English is the lingua franca of Internet use, and while we would expect that “national” search results would differ—there are more Web pages about Lisboa (Portuguese) than about Lisbon (English)—overall, the English language Web is vastly predominant (Internetworldstats.com 2009). Looking at these “national” Internets, either by searching in “national” languages, or else using Google’s national domains (Google.com being the US/international site, Google.pt being, for example, the Portuguese domain) would be an interesting and useful exercise. Thus, w hile English is undoubtedly the language of the Internet, there are other important “global” languages too (such as Chinese and Spanish) and repeating this analysis in these languages and deriving equivalent expressions for our key terms, would, we suggest, yield a somewhat different picture2. RESULTSIn this section we provide brief illustrations of our methods. First, we use the Google database to derive hierarchical informational rankings of the 100 largest cities, in terms of population (Demographia.com 2009), based on quantitative hyperlink criteria, that is, the cities’ informational prominence in respect of the global financial crisis (deriving GFSs or global financial scores) and in respect of global climate change (deriving GESs or global environmental scores). Second, we demonstrate that the quantity of information about a place tells only part of the story. A more comprehensive perspective can be obtained by analyzing the specific content of Web information related to each city. Finally, we use some preliminary data from our language research to illustrate the impact of language on the rankings presented below. Ranking Cities on Hyperlink VolumeIn a first attempt to examine how the present global economic crisis is affecting major cities on the planet and how they are responding to global financial and environmental crises, we ranked 100 major cities globally through a quantitative hyperlink analysis. This real-time information analysis was conducted on 12 February 2009 utilizing, as mentioned above, a script that runs queries in Google synchronously. As we are interested in differences between developed versus developing cities, global cities versus large cities, western versus eastern cities, etc., the cities’ selection was not based on pure financial criteria (as in the GaWC list, see www.lboro.ac.uk/gawc) but on population (see demographia.com). This data source leads to a broader, more representative global coverage: Australia (3 cities), East Asia (23), Europe (9), Greater Middle East (8), Latin America (15), North America (15), Russia (2), South Asia (11), Southeast Asia (7), and Sub Saharan Africa (7)3. The hyperlink volume analysis presented here is two-fold. Firstly, we look at the absolute numbers of hits for each of the hundred cities in combination with two financial terms and the two environmental topics. That is, we have four data entries for each city. Second, we examine briefly the relationships between London, and Hong Kong, and the other 99 cities as an example of an inter-city relationship analysis. In order to obtain an informational perspective on the impact of the economic and environmental crises on (and the representation of their relationship with) the 100 cities, we firstly measure the absolute number of entries that appeared when searching on an information term and city name simultaneously in the Google database. In order to rank the cities under the Global Economic Crisis, we opt for two different search terms, that is, “global financial crisis” and “economic slowdown”; for the Global Environmental Crisis we searched on “global warming” and “climate change”. This resulted in four different rankings. For example, searching for the number of (Google) Web pages that jointly mention “Chicago” and “climate change” resulted in 395,000 entries. However, as the correlation between the financial and environmental topics is relatively high (Pearson’s r is respectively 0.96 and 0.95), we introduced a GFS (global financial score) and a GES (global environmental score) based on the average hyperlink volume of both financial and environmental terms respectively. Figures 2a and b present the 50 cities with the highest GFS and GES respectively.
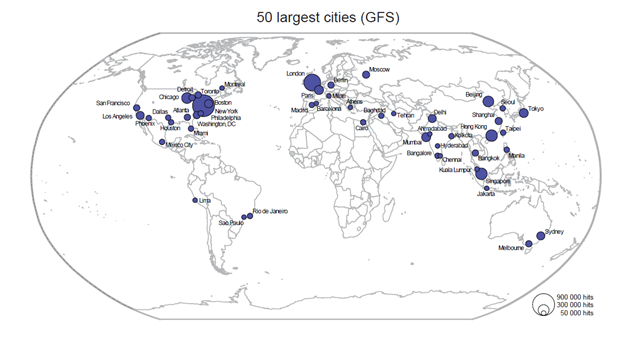
Figure 2a: 50 most important cities in terms of GFS (Global Financial Score)
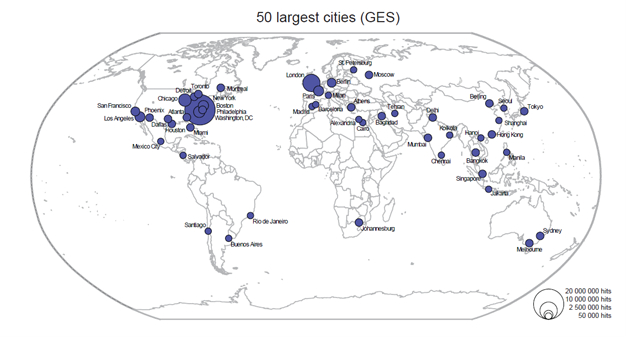
Figure 2b: 50 most important cities in terms of GES (Global Environmental Score)
We might expect that the larger the city or agglomeration, the greater the number of search results. However, there is no direct correlation between population size and the GES or GFS (e.g., Pearson’s r for GES and GFS with population are 0.25 and 0.37 respectively). In other words, the volume of information for a city does not depend on the city’s size but on its informational importance on these topics. The information volumes differ, furthermore, between GES and GFS in that there is, not surprisingly, a higher number of environmental hits overall in comparison to financial hits. The salience of the climate change topics over a longer period of time, as shown in Figure 1 (above) resulted in a higher information volume in Google on climate change topics than on information about the current financial crisis (40 in comparison to 18 million hits). This tallies with the Google Trends data on the number of searches performed (Figure 1) where the frequency of searches for climate change-related topics over the period since 2004 exceeds the search frequency for financial crisis related topics five-fold. There are, as expected, regional differences in the rankings based on the economic and environmental measures. Cities in developed countries tend to have more hits than in developing countries: North American and European cities have in general more hits than cities located in Sub Saharan Africa, Greater Middle East, or Latin America. South and East Asian cities fall somewhere between these clusters. The dominant cities are for both scores London and New York. In other words, New York and London live up to their reputation as important global cities which rank as the most important cities in terms of both environmental and financial data. Searching for both cities yields large volumes of information on both topics. Tokyo, the third global city of Sassen’s global triad (1991), takes place nine for GFS and ten for GES (Pearson’s r for 89 comparable cities of the GaWC-ranking (Taylor 2001, Global Network Service Connectivities for 315 Cities in 2000) are 0.75 and 0.60 for GFS and GES and the GaWC-data respectively). Ranking on GFS, the most important cities beyond New York and London are Singapore, Hong Kong, Beijing, Chicago, and Mumbai. Ranking on GES, we get Chicago, Washington, DC, Paris, Boston, and Los Angeles. Thus, while for environmental topics the more traditional western developed world come to the fore, we obtain for the financial topics relatively more Asian cities in the top fifty (10% more Asian cities ranked in terms of GFS/GES). There are in other words different kinds of information volumes when going down the urban hierarchy. The second part of our analysis looked at the relationships between cities in this information database. By combining two cities with one information term, we assembled four 100 x 100 city matrices on two financial and two environmental topics. Searching, for example, for the number of (Google) web pages that jointly mention “London”, “Tokyo”, and “global financial crisis” resulted in 151,950 entries (e.g., “London AND Tokyo AND ‘global financial crisis’”). Although this huge volume of gathered information is interesting to compare differences between regions, developed versus developing cities, global versus large cities, etc., in this paper, we provide only some preliminary results. We single out the case of London and Hong Kong (two global financial cities) for this relationship-based search in combination with the term “global financial crisis” (see Table 1).
Table 1: Fifteen most important city relationships of Hong Kong and London with the other 99 largest cities, ranked on hits for ‘global financial crisis’.
Table 1 shows the most important relationships of Hong Kong and London in terms of information on the global financial crisis. What is most striking are the ‘regional’ differences between the urban linkages for both cities: Paris is the fourth strongest link with London, while for Hong Kong Paris is ranked fifteenth. The inverse could be said for Seoul and both cities—ranking fifteenth in terms of connection with London, and fifth in terms of connection with Hong Kong. Regionality plays in other words an important role for the information linkages (other examples are the links with Shenyang, Shanghai, etc. for Hong Kong, and Berlin for Paris). However, in general, the top linked cities are for both cities New York, Singapore, and Tokyo. Content AnalysisIn order to understand the types as well as the quantity of financial and environmental information associated with each of the 100 largest cities in our database, we carried out a content analysis of the top-ranked search results for each city. The pages were analyzed within a 24 hour period between February 27 and February 28, 2009. In terms of the global financial crisis, which we illustrate in this section, we used Google to search “global financial crisis and [city name]”, and analyzed the first SERP (search engine results page) for each city in turn. Our web content sample, that is, the first page of Google results for each query, is justified on the following grounds: first, Google’s algorithms and PageRank allocate these as the most important/relevant results for our query. Second, given these rankings, we are interested in those issues about the financial crisis that are most strongly associated with each city. Using the first pages of results about a city for each query is not without its problems. The more-or-less legitimate processes of Search Engine Optimization (that is, the “boosting” of sites’ rankings within the Google index) including the practice of “incestuous linking” (a small group of Web sites using self-referential hyperlinks to boost their PageRank) need to be taken into account. Also the “reading” or classifying of web content also required some qualitative vetting of information. In our analysis Web pages were dismissed if they did not relate directly to the city and topic of the search query. Often, and particularly this was the case of less well “connected” cities (with respect total hits/hyperlinks), search results included pages that were essentially lists of hyperlinked keywords intended to drive traffic to largely useless and content-free Web pages, or news portals. For example: the news archive/portal of The Tribune, a popular Indian daily newspaper (http://www.tribuneindia.com/2008/20081003/world.htm) showed up in the search for “‘global financial crisis’ AND Kinshasa” because it links to news stories that reference the global financial crisis and Kinshasa separately, but not jointly. Such irrelevant or otherwise non-substantive Web pages were dismissed. Our sample of approximately ten Web “pages” per city yielded, on average, approximately four relevant and unique topics per city. Spamming is an ever present annoyance to users, a challenge to search companies, and a real issue in our use of the Google database for our research. Search algorithms are more complex than they once were, but that seems to raise the stakes for companies and individuals, legitimate or otherwise, whose livelihoods (or at, least, additional income) depend crucially on their web sites’ rankings in search results. Empirical studies suggest that the degree of trust users place in Google-derived search results is high (Pan et al. 2007); very few users will look beyond the first handful of search results returned for a given search query, and will tend to believe Google’s rankings to be objective or otherwise credible. Our content analysis is conducted in full recognition of these limitations. Few users understand even in part, none fully, the mechanisms by which a search engine locates the information they search for (Introna and Nissenbaum 2000), and as Hindman et al. (2003) note, this blind trust placed in search results bodes ill for the democratization of information when existing informational hierarchies are reinforced by repetitive reaffirmation (through user click-throughs) and privileging of highly ranked information. That, statistically, few users venture beyond the first page of search results for a given topic suggests the methodological desirability to analyze in some detail the most popular Web results for our topics of interest. Following the inductive framing approach of Semetko and Valkenburg (2000), the Web pages were initially read openly with (insofar as is possible) no preconceived notion of the likely results. A lengthy matrix was compiled listing unique and substantive topics relating to the global financial crisis for each of the 100 cities. After an initial reading of the Web pages, we wrote short (one to two sentence) abstracts of the pages’ content. These qualitative summaries were collapsed first into a series of 54 subjects and subsequently into ten core categories, viz: (1) Foreign aid, investment and loans; (2) Financial sector and markets; (3) Effects on specific (sub)populations; (4) Effects on local governments and services; (5) Solutions/plans; (6) Social and political effects; (7) Real estate and property market; (8) Losses/cuts; (9) ICT economies; (10) Bright side: low gas prices, sustainable architecture, safe investments.
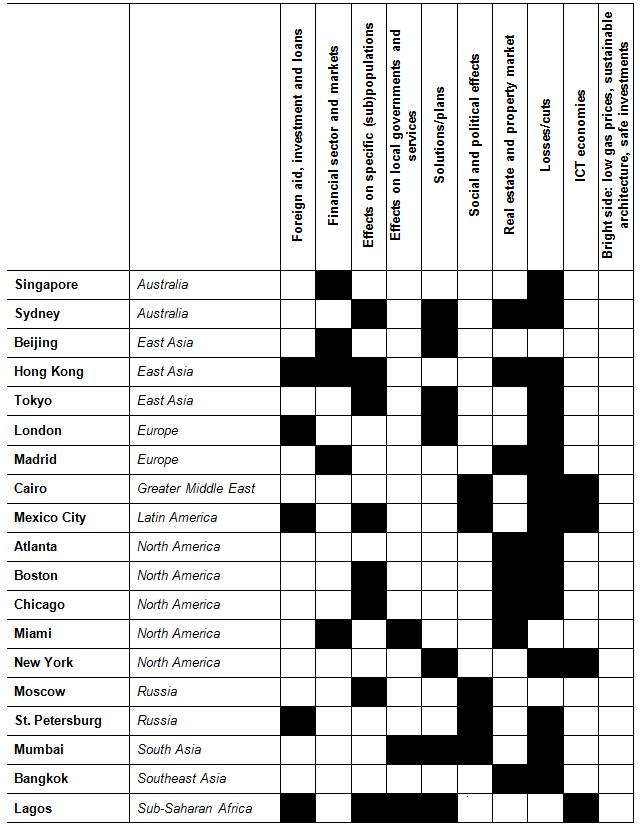
Table 2: Financial topics
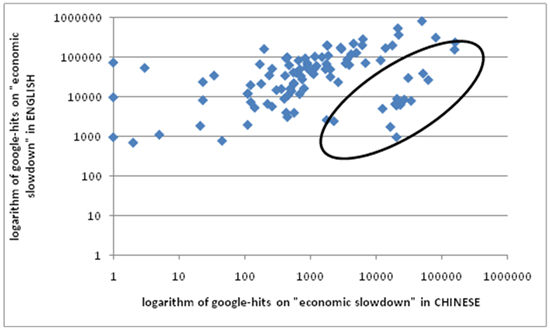
Table 2 illustrates the occurrence of financial topics for a number of key cities. Our cautions about Web content analysis are well founded. Of the more than 1000 Web pages analyzed, only 307 were found to be “relevant” (in our definition above). The table visualizes a strong regionality to the results (note, for example, the universality of “losses” and cutbacks, and the prominence of real estate and property that were important in North American cities whereas the “social and political effects”, labor organization or other kinds of unrest and protest were absent in the North American context). The Influence of LanguageAs a preliminary exercise in understanding the effect of language on our ranking scheme (outlined in subsection 1, above), we repeated our “GFS” analysis to obtain ranks for cities, based on financial data using search terms in Chinese. We used an equivalent Chinese language phrase, “economic slowdown”, to ensure it is the most widely used Chinese descriptor of the topic, we compared the number of hits for each of the 100 cities in English with the number of hits in Chinese. Figure 3 shows a strong, positive relationship between results volumes in Chinese and English: that is, cities with highest GFS scores in the English database tended to have correspondingly high scores in the Chinese database. Note, however, the cluster of Chinese cities (highlighted) with substantially more links in Chinese relative to English. This finding suggests that there is something of a language effect to be considered, viz., that the cyberspaces of the world urban system have distinctive regional variations.
Figure 3: Language Impact on Hyperlink Analysis
DISCUSSION AND CONCLUSIONSThis paper has argued for the need to move beyond infrastructural “cyberplace” approaches to characterizing inter-city differentiations to a “cyberspace” approach that is appropriate to understanding the current global urban hierarchy as in part a product of untethered and intangible flows of information. Place or absolute location matters, but so does the space of flows in which cyberspace is continuously reconfigured in real-time reflecting and impacting upon the material world. While previous studies lament the unavailability of appropriate data to measure information flows, we have suggested that the problem is rather one of making judicious use of the vast database that Google represents. We believe the lines of inquiry outlined above can be used to further understand the contemporary fluid nature of urban economic worlds. Our ongoing research focuses on four major topics: (i) Broadening the Dataset We plan to increase the number of cities from 100 to 1300 (using Demographia database). Although this increase will lead to more problems in what we before discussed under ‘ambivalent search terms’ (e.g., Birmingham, US versus UK), we believe it will provide us an opportunity to compare a broader range of cities on a much more global scale. We are also interested in classifying cities by region, to the extent that we are able: developing versus developed; coastal versus inland, traditional global cities (e.g., New York, London) versus new global cities (e.g., Asian and Middle East cities); Indian versus Chinese cities; Europe versus North America, etc. We also want to examine differences in the information volume and content on the financial and environmental topics of the largest 100 cities. Furthermore, we would like to look at the bottom 200 (of the top 1300) cities in terms of population to discern if similar patterns exist as for those cities they are most connected. (ii) Categorizing Inter-city Relationships In Section III.1., we presented some preliminary results of a hyperlink analysis on the relationships between cities. The huge database we created (four 100 x 100 matrices) contains a large volume of information to examine and discuss. At first glance, it seems a city’s relationships depends on regionality. Our aim is to identify other determinants of connection, for example: a city’s physical location (coast/inland) or status (primary city or not). We aim to discuss this further and use advanced mappings to present the results. (iii) The Importance of Language In order to understand the effect of language on city ranking, we translated the cities’ (and search term) list into Chinese and repeated our analysis (see section III.3.). The results suggested that there is a language effect that must be considered: Chinese cities have higher hyperlink volumes in the Chinese language analysis, especially in terms of their connection to other Chinese cities. To understand this language problem better, we aim to enlarge this language exercise and look also at other dominant languages (e.g., Spanish, Portuguese, French, etc.). Enlarging the Chinese test with other topics is therefore another avenue for further research. (iv) Time Line Project Beginning in February 2009, we engaged in a year-long project to monitor the temporal change in city rankings in respect of the global economic and environmental crisis. These data will give us the opportunity to illustrate the fluctuating salience through time of the cities’ rankings based on the topics used in our analysis. We aim to examine the differences in information volumes in relation to major events, and to identify any shifting regional variations. ACKNOWLEDGEMENTDevriendt, L., Boulton, A., Brunn, S., Derudder, B. and Witlox, F. contributed equally to the research and writing of this article and take responsibility for any errors or omissions. The research work is funded by the Research Foundation–Flanders. REFERENCESAlderson, A. and J. Beckfield (2004) Power and position in the world city system. American Journal of Sociology, 109, pp. 811–851. Bakis, H. (1993) Economic and social geography - toward the integration of communications networks studies. In: H. Bakis, R. Abler, and R. Roche (Eds.). Corporate networks, international telecommunications and interdependence. London: Belhaven Press, pp. 1-15. Beaverstock, J., Smith, R. and P. J. Taylor (2000a) World city network: a new metageography? Annals of the Association of American Geographers 90(1), pp. 123-134. Beaverstock, J., Smith, R., Taylor, P., Walker, D. and H. Lorimer (2000b) Globalization and world cities: some measurement methodologies. Applied Geography 20(1), pp. 43-63. Brunn, S. (2003) A note on the hyperlinks of major Eurasian cities. Eurasian Geography and Economics 44 (4), pp. 321-324. Castells, M. (1996) The Rise of the Network Society. Oxford, Blackwell. Castells, M. (2000) The Rise of the Network Society. Second Edition. Oxford, Blackwell. Choi, J. H., Barnett, G.A., Chon, B.-S. (2006) Comparing world city networks: a network analysis of Internet backbone and air transport intercity linkages. Global Networks 6(1), pp. 81-99. Crutcher, M. and M. Zook (2009) Placemarks and waterlines: racialized cyberscapes in post-Katrina Google Earth. Geoforum, in press. Davis, K. (1959) The World’s Metropolitan Areas. Berkeley, University of California Press de Vries, I. (2006) Propagating the ideal: the mobile communication paradox. In: S. Van Der Graaf and Y. Washida (Eds.). Information Communication Technology and Emerging Business Strategies. Hershey, PA: Ideas Group, pp. 1-19. Demographia. (2009) www.demographia.com. Last accessed 10/06/09, 2009. Derudder, B. (2006) On conceptual confusion in empirical analyses of a transnational urban network. Urban Studies 43(11), pp. 2027-2046. Derudder, B., Devriendt, L., and F. Witlox (2007) Flying where you don’t want to go: an empirical analysis of hubs in the global airline network. Tijdschrift voor Economische en Sociale Geografie 98(3), pp. 307-324. Devriendt, L., Derudder, B. and F. Witlox (2008) Cyberplace and Cyberspace: two approaches to analyzing digital intercity linkages. Journal of Urban Technology 15(2), pp. 5-32. Dodge, M. and N. Shiode (2000) Where on Earth is the Internet? An empirical investigation of the geography of the Internet real estates. In: J. Wheeler, Y. Aoyama, and B. Warf (Eds.). Cities in the Telecommunications Age: the fracturing of Geographies (pp. 42-53). London: Routledge, pp. 42-53. Dodge. M. and R. Kitchin (2001) Mapping cyberspace. London: Routledge. Dourish, P. (2006) Re-space-ing place: “place” and “space” ten years on Proceedings of the 2006 20th anniversary conference on Computer supported cooperative work. Available from: http://portal.acm.org/citation.cfm?id=1180921. Last accessed: 05/05/2009. Dutta, S. and I. Mia (2007) Executive summary. In: World Economic Forum The Global Information Technology Report 2007-8. http://www.insead.edu/v1/gitr/wef/main/fullreport/index.html. Last accessed: 05/05/2009. Friedmann, J. (1986) The world city hypothesis. Development and Change 17, pp. 63-83. Friedmann, J. (1995) Where we stand: a decade of world city research. In: P. Knox and P. Taylor (Eds.). World Cities in a World System. New York: Cambridge University Press, pp. 21-47. GaWC (Global and World Cities) Study and Network. Loughborough University, United Kingdom. www.lboro.ac.uk/gawc. Last accessed: 05/05/2009. GlobalStats (2009) Top 5 search engines (1 July 08 to 10 June 09). http://gs.statcounter.com/#search_engine-ww-daily-20080701-20090610. Last accessed 10/06/09. Google.com (2009) www.google.com. Last accessed: 05/05/2009. Hall, P. (1966) The World Cities. New York, McGraw-Hill. Hall, P. (2001) Global city-regions in the twenty-first century. In: A. Scott (Ed.). Global City regions: Trends, Theory, Policy. Oxford: Oxford University Press, pp. 59–77. Hanley, R. (2004) Moving People, Goods and Information in the 21st Century: The Cutting-Edge Infrastructures of Networked Cities. London-New York, Routledge. Hillis, K. (1998) On the margins: the invisibility of communications in geography. Progress in Human Geography 22(4), pp. 543-566. Hindman, M., Tsioutsiouliklis, K. and J. Johnson (2003) Googlearchy: how a few heavily-linked sites dominate the Web. Presented at the Midwest Political Science Association, Chicago. Available from: http://www.cs.princeton.edu/~kt/mpsa03.pdf. Last accessed: 05/05/2009. Internetworldstats.com (2009) www.internetworldstats.com. Last accessed: 05/05/2009. Introna, L and Nissenbaum (2000) The politics of search engines. IEEE Spectrum 37(6), pp. 26-7 Jefferson, M. (1939) The law of the primate city. Geographical Review 29, pp. 226-232. Jefferson, M. (1940) The great cities of the United States, 1940. Geographical Review 31, pp. 478-487. Kellerman, A. (2002) The Internet on Earth. A Geography of Information. West Sussex, England, John Wiley & Sons Ltd. Knox, P. (1994) Urbanization: An Introduction to Urban Geography. Englewood Wliffs, NJ, Prentice Hall. Knox, P. and Taylor, P. (1995) World Cities in a World System. Cambridge, UK: Oxford University Press. Malecki, E. (2002) The economic geography of the Internet’s infrastructure. Economic Geography 78, pp. 399-424. Marketshare.hitslink.com (2009) http://marketshare.hitslink.com/search-engine-market-share.aspx?qprid=4. Last accessed: 05/05/2009. Mitchelson, R. and J. Wheeler (1994) The Flow of Information in a Global Economy - the Role of the American Urban System in 1990. Annals of the Association of American Geographers 84(1), pp. 87-107. Netcraft (2009) www.netcraft.com. Last accessed: 05/05/2009. Ohmae, K. (1990) The Borderless World: power and strategy in the interlinked economy. London: HarperCollins. Pan, B., Hembrooke, H., Joachims, T., Lorigo, L., Gay, G. and L. Granka (2007) In Google We Trust: users’ decisions on rank, position, and relevance. Journal of Computer-Mediated Communication 12(3), article 3. Paradiso, M. (2003) Geography of the information society: a new culture of hybrid spaces? Presented at The Cultural Turn in Geography conference, University of Trieste. Available from: http://www.openstarts.units.it/dspace/handle/10077/824. Last accessed: 05/05/2009. Pred, A. (1980) Urban Growth and City Systems in the United States, 1840-1860. Hutchinson, London. Rutherford, J., Gillespie, A. and R. Richardson (2004) The territoriality of Pan-European telecommunications backbone networks. Journal of Urban Technology 11(3), pp. 1-34. Sassen, S. (1991) The Global City: New York, London, Tokyo. Princeton, Princeton University Press. Semetko, H. and P. Valkenburg (2000) Framing European politics: a content analysis of press and television news. The Journal of Communication 50(2), pp. 93-109. Sheller, M. and J. Urry (2006) The new mobilities paradigm. Environment and Planning A 38(2), pp. 207-226. Short, J., Kim, Y., Kuss, M. and H. Wells (1996) The dirty little secret of word city research. International Journal of Regional and Urban Research 20, pp. 697-717. Smith, D. and M. Timberlake (2001) World city networks and hierarchies, 1977-1997. An empirical analysis of global air travel links. American Behavioral Scientist 44(10), pp. 1656-1678. Taylor, P. (1997) Hierarchical tendencies amongst world cities: a global research proposal. Cities 14, pp. 323–332. Taylor, P. (2001) Specification of the world city network. Geographical Analysis 33, pp. 181-194. Taylor, P. (2004) World City Network: A Global Urban Analysis. London: Routledge. Williams, J. and S. Brunn (2004) Cybercities of Asia: measuring globalization using hyperlinks (Asian Cities and Hyperlinks). Asian Geographer 23 (1-2): pp. 121-147. Zook, M. and S. Brunn (2006) From podes to antipodes: positionalities and global airline geographies. Annals of the Association of American Geographers 96(3), pp. 471-490.NOTES* Lomme Devriendt, Ben Derudder, Frank Witlox, Ghent University - Department of Geography, e.: lomme.devriendt@ugent.be; ben.derudder@ugent.be; frank.witlox@ugent.be, w: http://www.geoweb.ugent.be/seg ** Andrew Boulton, Stanley Brunn, University of Kentucky - Department of Geography, e.: andrew.boulton@uky.edu; stan.brunn@uky.edu, w: http://www.uky.edu/AS/Geography 1. What’s in a name? Microsoft has named his recently developed ‘search engine’ ‘Bing’ not a search engine but a decision engine, which aims to provide users with a "first step in moving beyond search to help make faster, more informed decisions." (www.bing.com) 2. The top three Internet languages are according to Internet World Stats English (29,1%), Chinese (20,1%), and Spanish (8,1%) (Internetworldstats.com 2009). 3. Cities are given in the appendix. APPENDIX
Note: This Research Bulletin has been published in Journal of Urban Technology, 18 (1), (2011), 73-92 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||